Knowing how to check if a Python string contains a substring is a very common thing we do in our programs.
In how many ways can you do this check?
Python provides multiple ways to check if a string contains a substring. Some ways are: the in operator, the index method, the find method, the use of a regular expressions.
In this tutorial you will learn multiple ways to find out if a substring is part of a string. This will also give you the understanding of how to solve the same problem in multiple ways using Python.
Let’s get started!
In Operator to Check if a Python String Contains a Substring
The first option available in Python is the in operator.
>>> 'This' in 'This is a string'
True
>>> 'this' in 'This is a string'
False
>>> As you can see the in operator returns True if the string on its left is part of the string on its right. Otherwise it returns False.
This expression can be used as part of an if else statement:
>>> if 'This' in 'This is a string':
... print('Substring found')
... else:
... print('Substring not found')
...
Substring foundTo reverse the logic of this if else statement you can add the not operator.
>>> if 'This' not in 'This is a string':
... print('Substring not found')
... else:
... print('Substring found')
...
Substring foundYou can also use the in operator to check if a Python list contains a specific item.
Index Method For Python Strings
I want to see how else I can find out if a substring is part of a string in Python.
One way to do that is by looking at the methods available for string data types in Python using the following command in the Python shell:
>>> help(str)In the output of the help command you will see that one of the methods we can use to find out if a substring is part of a string is the index method.

The string index method in Python returns the index in our string where the substring is found, otherwise it raises a ValueError exception
Let’s see an example:
>>> 'This is a string'.index('This')
0
>>> 'This is a string'.index('is a')
5
>>> 'This is a string'.index('not present')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not foundIn the first example the index method returns 0 because the string ‘This’ is found at index zero of our string.
The second example returns 5 because that’s where the string ‘is a’ is found (considering that we start counting indexes from zero).
In the third example the Python interpreter raises a ValueError exception because the string ‘not present’ is not found in our string.
The advantage of this method over the in operator is that the index method not only tells us that a substring is part of a string. It also tells us at which index the substring starts.
Find Method For Python Strings
While looking at the help page for strings in Python I can see another method available that seems to be similar to the index method. It’s the find method.
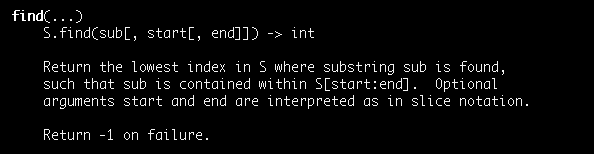
The string find method in Python returns the index at which a substring is found in a string. It returns -1 if the substring is not found.
Let’s run the same three examples we have used to show the index method:
>>> 'This is a string'.find('This')
0
>>> 'This is a string'.find('is a')
5
>>> 'This is a string'.find('not present')
-1As you can see the output of the first two examples is identical. The only one that changes is the third example for a substring that is not present in our string.
In this scenario the find method returns -1 instead of raising a ValueError exception like the index method does.
The find method is easier to use than the index method because with it we don’t have to handle exceptions in case a substring is not part of a string.
Python String __contains__ Method
I wonder how the in operator works behind the scenes, to understand that let’s start by creating a new string and by looking at its attributes and methods using the dir function:
>>> test_string = 'This is a string'
>>> dir(test_string)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']I want to focus your attention on the __contains__ method.
Let’s see if we can use it to check if a substring is part of a string:
>>> test_string.__contains__('This')
True
>>> test_string.__contains__('this')
FalseIt works in the same way the in operator does.
So, what’s the difference between the two?
Considering that the method name starts with double underscore “__”, the method should be considered “private” and we shouldn’t call it directly.
The __contains__ method is called indirectly when you use the in operator.
It’s something handy to know! 🙂
Search For Substring in a Python String Using a Regular Expression
If we go back to the in operator I want to verify how the operator behaves if I want to perform a case insensitive check.
>>> 'this' in 'This is a string'
FalseThis time the in operator returns False because the substring ‘this’ (starting with lower case t) is not part of our string.
But what if I want to know if a substring is part of a string no matter if it’s lower or upper case?
How can I do that?
I could still use the in operator together with a logical or:
>>> 'This' in 'This is a string' or 'this' in 'This is a string'
TrueAs you can see the expression works but it can become quite long and difficult to read.
Imagine if you want to match ‘This’, ‘this’, ‘THIS’…etc..basically all the combinations of lower and uppercase letters. It would be a nightmare!
An alternative is provided by the Python built-in module re (for regular expressions) that can be used to find out if a specific pattern is included in a string.
The re module provides a function called search that can help us in this case…
Let’s import the re module and look at the help for the search function:
>>> import re
>>> help(re.search)
Using the search function our initial example becomes:
>>> import re
>>> re.search('This', 'This is a string')
<re.Match object; span=(0, 4), match='This'>We get back a re.Match object?!?
What can we do with it? Let’s try to convert it into a boolean…
>>> bool(re.search('This', 'This is a string'))
True
>>> bool(re.search('Thiz', 'This is a string'))
FalseYou can see that we get True and False results in line with the search we are doing. The re.search function is doing what we expect.
Let’s see if I can use this expression as part of an if else statement:
>>> if re.search('This', 'This is a string'):
... print('Substring found')
... else:
... print('Substring not found')
...
Substring found
>>>
>>> if re.search('Thiz', 'This is a string'):
... print('Substring found')
... else:
... print('Substring not found')
...
Substring not foundIt works with an if else statement too. Good to know 🙂
Insensitive Search For Substring in a Python String
But what about the insensitive check we were talking about before?
Try to run the following…
>>> re.search('this', 'This is a string')…you will see that it doesn’t return any object. In other words the substring ‘this’ is not found in our string.
We have the option to pass an additional argument to the search function, a flag to force a case insensitive check (have a look at the help for the search function above, it’s right there).
The name of the flag for case insensitive matching is re.IGNORECASE.
>>> re.search('this', 'This is a string', re.IGNORECASE)
<re.Match object; span=(0, 4), match='This'>This time we get an object back. Nice!
Check If a Python String Contains Multiple Substrings
It’s very common having to check if a string contains multiple substrings.
Imagine you have a document and you want to confirm, given a list of words, which ones are part of the document.
In this example we are using a short string but imagine the string being a document of any length.
document = "The Python programming language was created by Guido van Rossum"
words = ["Python", "Rossum", "substring"]We want to find out which elements of the list words are inside the string document.
Let’s start with the most obvious implementation using a for loop:
words_found = []
for word in words:
if word in document:
words_found.append(word)Here is the content of the list words_found:
>>> words_found
['Python', 'Rossum']But, what happens if the list words contains duplicates?
words = ["Python", "Rossum", "substring", "Python"]In this case the list words_found contains duplicates too:
>>> words_found
['Python', 'Rossum', 'Python']To eliminate duplicates from the list of substrings found in the document string, we can add a condition to the if statement that checks if a word is already in the list words_found before adding it to it:
words_found = []
for word in words:
if word in document and word not in words_found:
words_found.append(word)This time the output is the following (it doesn’t contain any duplicates):
>>> words_found
['Python', 'Rossum']Checking For Multiple Substrings in a String Using a List or Set Comprehension
How can we do the same check implemented in the previous section but using more concise code?
One great option that Python provides are list comprehensions.
I can find out which words are part of my document using the following expression:
>>> words_found = [word for word in words if word in document]
>>> words_found
['Python', 'Rossum', 'Python']That’s pretty cool!
A single line to do that same thing we have done before with four lines.
Wondering how we can remove duplicates also in this case?
I could convert the list returned by the list comprehension into a set that by definition has unique elements:
>>> words_found = set([word for word in words if word in document])
>>> words_found
{'Rossum', 'Python'}Also, in case you are not aware, Python provides set comprehensions. Their syntax is the same as list comprehensions with the difference that square brackets are replaced by curly brackets:
>>> words_found = {word for word in words if word in document}
>>> words_found
{'Rossum', 'Python'}Makes sense?
Check If a String Contains Any or All Elements in a List
Now, let’s say we only want to know if any of the elements in the list words is inside the string document.
To do that we can use the any() function.
The any() function is applicable to iterables. It returns True if any of the items in the iterable is True, otherwise it returns False. It also returns False if the iterable is empty.
Once again, here are the variables we are using in this example:
document = "The Python programming language was created by Guido van Rossum"
words = ["Python", "Rossum", "substring"]In the previous section we have used the following list comprehension that returns the words inside our string:
words_found = [word for word in words if word in document]Now, we will do something slightly different. I want to know if each word in the words list is in the document string or not.
Basically I want as a result a list that contains True or False and that tells us if a specific word is in the string document or not.
To do that we can change our list comprehension…
…this time we want a list comprehension with boolean elements:
>>> [word in document for word in words]
[True, True, False]The first two items of the list returned by the list comprehension are True because the words “Python” and “Rossum” are in the string document.
Based on the same logic, do you see why the third item is False?
Now I can apply the any function to the output of our list comprehension to check if at least one of the words is inside our string:
>>> any([word in document for word in words])
TrueAs expected the result is True (based on the definition of the any function I have given at the beginning of this section).
Before moving to the next section I want to quickly cover the all() function.
The all() function is applicable to iterables. It returns True if all the items in the iterable are True, otherwise it returns False. It also returns True if the iterable is empty.
If we apply the all() function to our previous list comprehension we expect False as result considering that one of the three items in the list is False:
>>> all([word in document for word in words])
FalseAll clear?
Identify Multiple String Matches with a Regular Expression
We can also verify if substrings in a list are part of a string using a regular expression.
This approach is not simpler than other approaches we have seen so far. But, at the same time, it’s another tool that you can add to your Python knowledge.
As explained before to use regular expressions in our Python program we have to import the re module.
The findall() function, part of the re module, returns matches of a specific pattern in a string as a list of strings.
In this case the list of strings returned will contain the words found in the string document.
import re
document = "The Python programming language was created by Guido van Rossum"
words = ["Python", "Rossum", "substring"]
re.findall('Python|Rossum|substring', document, re.IGNORECASE)As you can see we have used the or logical expression to match any of the items in the list words.
The output is:
['Python', 'Rossum']But imagine if the list words contained hundreds of items. It would be impossible to specify each one of them in the regular expression.
So, what can we do instead?
We can use the following expression, simplified due to the string join() method.
>>> re.findall('|'.join(words), document, re.IGNORECASE)
['Python', 'Rossum']And here is the final version of our program that applies the any() function to the output of the re.findall function.
import re
document = "The Python programming language was created by Guido van Rossum"
words = ["Python", "Rossum", "substring"]
if any(re.findall('|'.join(words), document, re.IGNORECASE)):
print("Match found")
else:
print("No match found")
Find the First Match in a String From a Python List
Before completing this tutorial I will show you how, given a list of words, you can find out the first match in a string.
Let’s go back to the following list comprehension:
[word for word in words if word in document]A simple way to find out the first match is by using the Python next() function.
The Python next() function returns the next item in an iterator. It also allows to provide a default value returned when the end of the iterator is reached.
Let’s apply the next function multiple times to our list comprehension to see what we get back:
>>> next([word for word in words if word in document])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'list' object is not an iteratorInteresting, we are seeing a TypeError exception being raised by the Python interpreter.
Do you know why?
The answer is in the error…
A list comprehension returns a list, and a list is not an iterator. And as I said before the next() function can only be applied to an iterator.
In Python you can define an iterator using parentheses instead of square brackets:
>>> (word for word in words if word in document)
<generator object <genexpr> at 0x10c3e8450>Let’s apply the next() function multiple times to the iterator, to understand what this function returns:
>>> matches = (word for word in words if word in document)
>>> next(matches)
'Python'
>>> next(matches)
'Rossum'
>>> next(matches)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIterationAs explained at the beginning of this section we can also provide a default value that is returned when we reach the end of the iterator.
>>> matches = (word for word in words if word in document)
>>> next(matches, "No more elements")
'Python'
>>> next(matches, "No more elements")
'Rossum'
>>> next(matches, "No more elements")
'No more elements'Going back to what we wanted to achieve at the beginning of this section…
Here is how we can get the first match in our string document:
document = "The Python programming language was created by Guido van Rossum"
words = ["Python", "Rossum", "substring"]
first_match = next((word for word in words if word in document), "No more elements")
print(first_match)Conclusion
We have started by looking at three different ways to check if a substring is part of a string:
- Using the in operator that returns a boolean to say if the substring is present in the string.
- With the index method that returns the index at which the substring is found or raises a ValueError if the substring is not in the string.
- Using the find method that behaves like the index method with the only difference that it returns -1 if the substring is not part of the string.
You have also seen how to find out if a string contains multiple substrings using few different techniques based on list comprehensions, set comprehensions, any() / all() functions and regular expressions.
And now that you have seen all these alternatives you have…
…which one is your favourite? 🙂

Claudio Sabato is an IT expert with over 15 years of professional experience in Python programming, Linux Systems Administration, Bash programming, and IT Systems Design. He is a professional certified by the Linux Professional Institute.
With a Master’s degree in Computer Science, he has a strong foundation in Software Engineering and a passion for helping others become Software Engineers.