Enumerate is a Python built-in function that not all developers know about.
It can be quite useful to simplify the way your programs are written and to avoid using indexes or counters with iterable objects. And avoid possible bugs!
Before looking at how enumerate() works we will have a look at Python loops written in two different ways and then compare how the code changes with enumerate.
Two Versions of a Python For Loop
First of all, let’s say I have a list with four elements I want to go through and also print the index for each element of the list.
countries = ['Italy', 'Greece', 'United Kingdom', 'Belgium']Version #1
A basic for loop in Python (that in Python behaves like a foreach for other programming languages) looks like this:
index = 0
for country in countries:
print(index, country)
index += 1As you can see, in order to print the index for each element we have to define an index variable outside of the loop and then increase its value at every iteration.
Here is the output:
0 Italy
1 Greece
2 United Kingdom
3 BelgiumIt’s not so bad, but using an index like this can become confusing if you have multiple indexes to manage for multiple lists.
Version #2
This time we use the Python range() function that has the ability to return a sequence of numbers.
Here’s how….
for x in range(6):
print(x)And the output is:
0
1
2
3
4
5So, how can we apply this to a for loop to print its elements and the index for each one of them?
We use the range() function to generate the indexes of the list and then use those indexes to access each element of the list and print it.
for index in range(len(countries)):
print(index, countries[index])The len function returns the length of the countries list, in this case 4.
And the output is:
0 Italy
1 Greece
2 United Kingdom
3 BelgiumIdentical to the output of the version #1 loop.
In this case we don’t have to keep track of the index with a variable defined by us, but I’m still not a huge fun of this syntax…something better is possible in Python.
Python Enumerate Applied to a For Loop
Now it’s the time to see how enumerate can simplify the way we write the for loop.
To understand what enumerate does we need to see first what it returns when applied to a list.
enumeratedCountries = enumerate(countries)
print(type(enumeratedCountries))
[output]
<class 'enumerate'>So, we get an enumerate object but it doesn’t really tell us much…
What’s inside this object?
Let’s see what happens if we convert it into a list:
print(list(enumeratedCountries))
[output]
[(0, 'Italy'), (1, 'Greece'), (2, 'United Kingdom'), (3, 'Belgium')]We have a list of tuples where the first element of each tuple is the index and the second element is the element of the countries list.
So, enumerate automatically tracks the index for each element in the list. That’s cool!
How does this help with our for loop?
for country in enumerate(countries):
print(country)
[output]
(0, 'Italy')
(1, 'Greece')
(2, 'United Kingdom')
(3, 'Belgium')With a for loop we can go through each tuple returned by the enumerate function.
What if we want to track the index in the same way we have done with the other two for loops?
Here is how you do it:
for index, country in enumerate(countries):
print(index, country)And the output is identical to the other two versions of the for loop, but with a lot cleaner syntax.
0 Italy
1 Greece
2 United Kingdom
3 BelgiumUsing Enumerate with a Start Index
Enumerate also accepts a second parameter (optional) that allows to decide which index to start the counter from.
If the optional start parameter is not present enumerate starts at 0 by default as we have already seen in our example.
Enumerate can start from 1 using the following syntax:
enumerate(countries, 1)I will change the for loop to start the count from 50:
for index, country in enumerate(countries, 50):
print(index, country)
[output]
50 Italy
51 Greece
52 United Kingdom
53 BelgiumSo, this is enumerate applied to lists in Python.
What else can we apply it to?
How to Enumerate Tuples and Lists of Tuples
As explained before the enumerate() function is applicable to iterable objects, another type of iterable data type in Python is the tuple.
Let’s convert the countries list into a tuple by changing the square brackets into round brackets:
countries = ('Italy', 'Greece', 'United Kingdom', 'Belgium')And use the enumerate function in a for loop:
for index, country in enumerate(countries):
print(index, country)
[output]
0 Italy
1 Greece
2 United Kingdom
3 BelgiumPretty simple…
In Python you can also mix different data types, for example, we can create a list of tuples as shown below and store a country and its capital in each tuple:
countries = [('Italy', 'Rome'), ('Greece', 'Athens'), ('United Kingdom', 'London'), ('Belgium', 'Brussels')]Then we use a for loop to print the index for each tuple and the capital for each country.
To access the elements of a tuple you can use the following syntax:
first_element = tuple_name[0]
second_element = tuple_name[1]So, the for loop becomes:
for index, country in enumerate(countries):
print("Index %d: the capital of %s is %s" % (index, country[0], country[1]))
[output]
Index 0: the capital of Italy is Rome
Index 1: the capital of Greece is Athens
Index 2: the capital of United Kingdom is London
Index 3: the capital of Belgium is BrusselsNotice the syntax we are using to print a string that contains variables. %d is used to print a number (the index) and %s is used to print a string (the capital and the country).
Using Enumerate with Other Data Types
I’m wondering if we can use enumerate with a Python string…
Does it make any sense?
At the end a string could be seen as a sequence of characters.
Let’s give it a try:
for index, character in enumerate(country):
print("Character index %d: %s" % (index, character))
[output]
Character index 0: I
Character index 1: t
Character index 2: a
Character index 3: l
Character index 4: yIt works! You can see that enumerate allows to track the index for each character in the string “Italy”.
How to Enumerate a Set and a Dictionary in Python
To understand if enumerate can be applied to sets and dictionaries we have to make a step back to data types in Python.
The ordering of items in sets is arbitrary and also the order of key / values in dictionaries is arbitrary. The same doesn’t apply to strings, lists and tuples that maintain the order of their items.
So, a sequence in Python is a data type that maintains the order of their items.
Let’s verify which one amongst strings, lists, tuples, sets and dictionaries is a sequence with a simple program:
- In the first line we import the Sequence class from the collections.abc module (abc stands for Abstract Base Classes…something that requires its own tutorial :)).
- The function isinstance(object, classinfo) is a built-in function that returns True if the object is an instance of type classinfo.
from collections.abc import Sequence
country_string = "Italy"
countries_list = ["Italy", "Greece", "United Kingdom", "Belgium"]
countries_tuple = ("Italy", "Greece", "United Kingdom", "Belgium")
countries_set = {"Italy", "Greece", "United Kingdom", "Belgium"}
countries_dictionary = {"Italy": "Rome", "Greece": "Athens", "United Kingdom": "London", "Belgium": "Brussels"}
print("country_string", type(country_string), isinstance(country_string, Sequence))
print("countries_list", type(countries_list), isinstance(countries_list, Sequence))
print("countries_tuple", type(countries_tuple), isinstance(countries_tuple, Sequence))
print("countries_set", type(countries_set), isinstance(countries_set, Sequence))
print("countries_dictionary", type(countries_dictionary), isinstance(countries_dictionary, Sequence))
[output]
country_string True
countries_list True
countries_tuple True
countries_set False
countries_dictionary FalseThis little program confirms that only strings, lists and tuples are sequences. So retrieving an index for sets and dictionaries doesn’t really make any sense.
Once again, as mentioned before, the order of items and keys / values in sets and dictionaries is arbitrary.
A for loop can simply be used to iterate over sets and dictionaries…
Here is how you do it with our set:
countries = {"Italy", "Greece", "United Kingdom", "Belgium"}
for country in countries:
print(country)
[output (first run)]
Belgium
United Kingdom
Greece
Italy
[output (second run)]
Greece
United Kingdom
Italy
BelgiumI have executed the for loop twice and as you can see the order in which the items of the set have been printed has changed. Another confirmation that the items of a set are unordered.
The interesting thing is that I can use the same identical for loop to print also elements from a list or a tuple that contain the same items.
For a list:
countries = ["Italy", "Greece", "United Kingdom", "Belgium"]
for country in countries:
print(country)
[output]
Italy
Greece
United Kingdom
BelgiumSimilarly for a tuple:
countries = ("Italy", "Greece", "United Kingdom", "Belgium")
for country in countries:
print(country)
[output]
Italy
Greece
United Kingdom
BelgiumYou can see why Python is quite cool and also easier to learn compared to other programming languages.
And finally let’s have a look at how to use the for loop with a dictionary:
countries = {"Italy": "Rome", "Greece": "Athens", "United Kingdom": "London", "Belgium": "Brussels"}
for country, capital in countries.items():
print("The capital of %s is %s" % (country, capital))
[output]
The capital of Italy is Rome
The capital of Greece is Athens
The capital of United Kingdom is London
The capital of Belgium is BrusselsIn a dictionary every item has the format key: value.
You now have a pretty good knowledge about Python data types.
Well done! 😀
Measuring the Performance of Enumerate in Python
Now that we have seen how enumerate works, we understand why it’s a lot easier to write a for loop using enumerate if we need to track the index of each item in a sequence.
But, which one of the ways of writing a for loop is better in terms of performance?
I will compare the follow implementations using the list below and the Python timeit module whose default number of execution is 1000000 (I won’t change it).
countries = ['Italy', 'Greece', 'United Kingdom', 'Belgium']Version #1
index = 0
for country in countries:
print(index, country)
index += 1Here is how you modify this code to use timeit and print the total duration of the test:
import timeit
code = """\
countries = ['Italy', 'Greece', 'United Kingdom', 'Belgium']
index = 0
for country in countries:
print(index, country)
index += 1"""
t = timeit.timeit(code)
print(t) I run this script and redirect the output to a file:
./python3 version1_test.py > output_v1The total execution time for version #1 is 4.727366327 seconds.
Version #2
for index in range(len(countries)):
print(index, countries[index])The total execution time for version #2 is 5.372164261 seconds.
Version #3
for index, country in enumerate(countries):
print(index, country)The total execution time for version #3 is 4.8059029010000005 seconds.
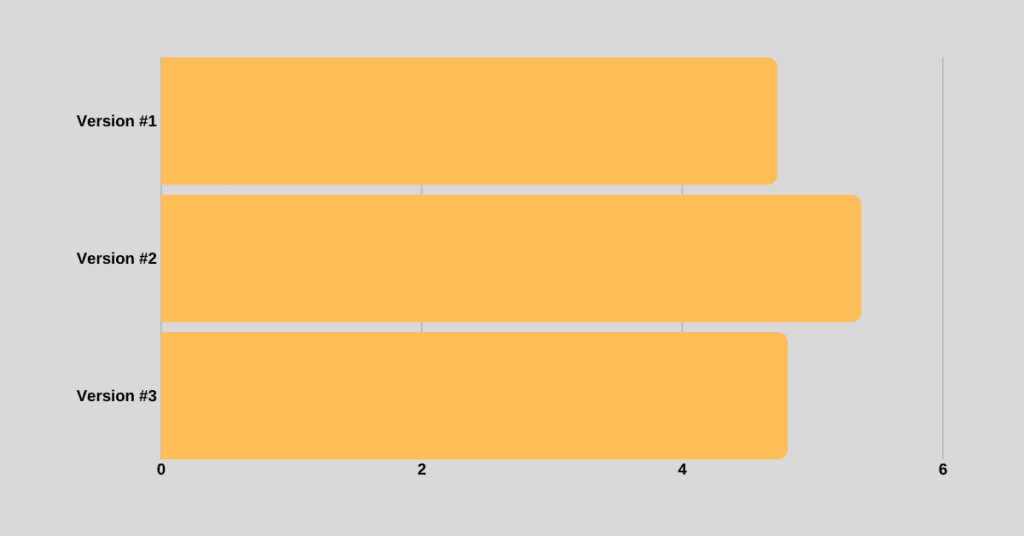
So, as you can see version #2 is the slowest implementation. Version #3 that uses enumerate is almost comparable to version #1.
Something to keep in mind to decide how you prefer to write your for loops 🙂
Conclusion
So, we have covered a lot in this tutorial:
- The traditional way of writing for loops in Python
- How a for loop changes with the enumerate function.
- Using a start index different than 0 with enumerate.
- Applying enumerate to lists, tuples, list of tuples and strings.
- Why enumerate doesn’t apply to sets and dictionaries.
- Measuring the performance of for loops with and without enumerate.
And you? Which way of writing a for loop do you prefer?
Will you be using the enumerate function in your Python programs?

Claudio Sabato is an IT expert with over 15 years of professional experience in Python programming, Linux Systems Administration, Bash programming, and IT Systems Design. He is a professional certified by the Linux Professional Institute.
With a Master’s degree in Computer Science, he has a strong foundation in Software Engineering and a passion for helping others become Software Engineers.