Sentiment analysis is a technique to extract emotions from textual data. This data may be used to determine what people actually believe, think, and feel about specific subjects or products.
Python’s popularity as a programming language has resulted in a wide range of sentiment analysis applications. The Natural Language Toolkit (NLTK) is a common library for sentiment analysis.
In this tutorial, you will learn the fundamentals to perform sentiment analysis using Python’s NLTK library.
How to Install and Import the NLTK Library in Python
You must first know how to install and import the NLTK library into your Python distribution before you can begin sentiment analysis with NLTK.
Pip is the default Python package installer, which you can use to install NLTK. Enter the following command into your command prompt:
pip install nltkOnce the installation is completed, you can import NLTK into your python environment as shown below:
import nltkNow you are good to go with NLTK sentiment analysis with Python.
Tokenization and Stop Words Removal with NLTK
We must first preprocess our text input before doing sentiment analysis.
The text must be modified, with stop words removed and words stemmed. NLTK offers several functions to achieve these objectives.
Let’s have a look at a few of these features:
How Do You Tokenize Text in Python?
Tokenization is the process of splitting text into discrete phrases or words. To do this, NLTK provides the word_tokenize() tokenizer part of the nltk.tokenize package.
A tokenizer converts a piece of text into a list of tokens and allows finding words and punctuation in the string.
The code snippet below uses a word tokenizer available in the NLTK library to split the given text into words.
from nltk.tokenize import word_tokenize
text = "Hello, today we will learn about Python Sentiment Analysis with NLTK."
tokens = word_tokenize(text)
print(tokens)When you execute this code you might see the following error:
LookupError:
**********************************************************************
Resource punkt not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt')The reason why you see the error “Resource punkt not found” is that this tokenizer needs Punkt sentence tokenization models to be installed on your machine.
To install Punkt sentence tokenization models run the following commands after opening the Python shell:
>>> import nltk
>>> nltk.download('punkt')Here is what it will look like when you do this on your computer:
>>> import nltk
>>> nltk.download('punkt')
[nltk_data] Downloading package punkt to
[nltk_data] /Users/codefather/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
TrueNow, execute the initial Python program to tokenize the string of text and confirm you see the following list of strings.
['Hello', ',', 'today', 'we', 'will', 'learn', 'about', 'Python', 'Sentiment', 'Analysis', 'with', 'NLTK', '.']As you can see we have split the text into words and punctuation.
Once again, in the code above, we have:
- imported the word_tokenize() tokenizer from the nltk.tokenize package.
- passed the text to analyze to word_tokenize().
- this function splits the text into words and punctuation.
As we will see later in this tutorial, NLTK also provides a sentence tokenizer to split text into sentences instead of words.
How to Remove Stopwords in Python
The text you analyze may contain words like “the”, “is”, and “an” that have no significance. These are called stop words and to remove them with Python you can use the NLTK library.
We can use NLTK’s stopwords.words that provides a list of stop words to exclude them from our analysis.
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
text = "Hello, today we will learn about Python Sentiment Analysis with NLTK."
tokens = word_tokenize(text)
print("Including stop words: ", tokens)
stop_words = set(stopwords.words('english'))
filtered_tokens = [token for token in tokens if token.lower() not in stop_words]
print("Excluding stop words: ", filtered_tokens)When you execute this code you might see the following error:
LookupError:
**********************************************************************
Resource stopwords not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('stopwords')In the same way, we have done before, open the Python shell and execute the following two Python statements.
>>> import nltk
>>> nltk.download('stopwords')Then execute the Python program and confirm you see the following output:
Including stop words: ['Hello', ',', 'today', 'we', 'will', 'learn', 'about', 'Python', 'Sentiment', 'Analysis', 'with', 'NLTK', '.']
Excluding stop words: ['Hello', ',', 'today', 'learn', 'Python', 'Sentiment', 'Analysis', 'NLTK', '.']In the code snippet above, we are extending the previous code to remove all the stop words present in our text. In this case, the stop words are:
- we
- will
- about
- with
We have imported all the English stopwords from the nltk.corpus package and then looped through the text to remove the stopwords using a Python list comprehension.
What Is the Meaning of Stemming in Python?
Stemming is the process of bringing a word to its root form. For example, the stem for the words “programming” or “programmer” is “program”.
As a result, the vocabulary we use shrinks but sentiment analysis becomes more accurate. PorterStemmer, SnowballStemmer, and other stemming algorithms are available in the NLTK library.
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer
text = "Python programming is becoming very popular."
tokens = word_tokenize(text)
stemmer = PorterStemmer()
stemmed_tokens = [stemmer.stem(token) for token in tokens]
print(stemmed_tokens)Here is what we get back when we use NLTK to perform the stemming process.
['python', 'program', 'is', 'becom', 'veri', 'popular', '.']In the code above, we are importing PorterStemmer from nltk.stem. We are tokenizing the text and then we pass the tokenized text to PorterStemmer.
This will break down words into their first form. For example, programming is stemmed to the simpler form program.
When I executed this code I was wondering why the stemmed form for very is veri. The reason is that the idea of stemming is to get a shorter version of a word to simplify sentiment analysis. At the same time, the shorter version might not have an actual meaning.
Let’s see a different process that given a word as input returns a shorter form that has a meaning.
What Is Lemmatization in Python?
Let’s have a look at the process called lemmatization which also brings words to their basic form. The difference from stemming is that with lemmatization you will obtain words that have a meaning.
Is lemmatization better than stemming? Let’s find out!
We will use as an example the same phrase we have stemmed previously and instead of using a stemmer, we use a lemmatizer.
from nltk.tokenize import word_tokenize
from nltk.stem.wordnet import WordNetLemmatizer
text = "Python programming is becoming very popular."
tokens = word_tokenize(text)
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in tokens]
print(lemmatized_tokens)To execute this code you will have to download the WordNet lexical database using the commands below in the Python shell:
>>> import nltk
>>> nltk.download('wordnet')Here is the output of the lemmatization process:
['Python', 'programming', 'is', 'becoming', 'very', 'popular', '.']Hmmm…the lemmatized version is identical to the original phrase.
The lemmatize method also accepts a second argument that represents the Part of Speech tag, for example in this case we can pass “v” which stands for “verb”.
Update the following piece of code and rerun the program:
lemmatized_tokens = [lemmatizer.lemmatize(token, "v") for token in tokens]Here is the output:
['Python', 'program', 'be', 'become', 'very', 'popular', '.']The verb “programming” has been lemmatized to “program” and the verb “becoming” to “become”.
We have seen some of the functions in the NLTK library. You should have now a better understanding of what NLTK is and how it works.
Now let’s jump into some sentiment analysis using NLTK.
How Does NLTK Do Sentiment Analysis?
In this example, we will use a sentiment analysis classifier called Vader (Valence Aware Dictionary for Sentiment Reasoning). Vader has already been trained in NLTK to categorize the sentiment intensity score of sentences as positive, negative, or neutral.
This pre-trained sentiment analysis classifier, which has a high degree of accuracy, was trained using a large dataset of text from social media. Given some text, it’s able to provide a sentiment score.
Let’s look at how you can use this classifier for sentiment analysis:
from nltk.sentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
text = "I love this product! It's amazing."
scores = analyzer.polarity_scores(text)
print(scores)In the code above, we import SentimentIntensityAnalyzer to see if a sentence is positive, negative, or neutral.
We pass some text to the classifier and then check the polarity score of the words. It will tell us whether the sentence has a positive or negative sentiment. In our case, the sentence is 73% positive.
{'neg': 0.0, 'neu': 0.266, 'pos': 0.734, 'compound': 0.8516}But…
What does compound mean in the output of the sentiment intensity analyzer?
The compound score is the sum of negative, neutral, and positive normalized to the range from -1 to +1, in other words, it represents the overall sentiment of the text. A compound score of +1 indicates a strong sense of positivity, whereas a score of -1 indicates a strong sense of negativity.
You can use these scores to categorize the sentiment of your text data.
Here is how we can compare the sentiment intensity of two sentences to understand which one is more positive than the other.
from nltk.sentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
review1 = "I love this product! It's amazing."
review2 = "This product is terrible. I hate it."
review1_score = analyzer.polarity_scores(review1)
print("Score for Review #1: {}".format(review1_score))
review2_score = analyzer.polarity_scores(review2)
print("Score for Review #2: {}".format(review2_score))
if review1_score['compound'] > review2_score['compound']:
print("The review that has a more positive sentiment is Review #1: \"{}\"".format(review1))
else:
print("The review that has a more positive sentiment is Review #2:\"{}\"".format(review2))The code above is self-explanatory, we are trying to classify two reviews as positive or negative based on the compound score calculated by a classifier.
Here are the scores of the two reviews:
Score for Review #1: {'neg': 0.0, 'neu': 0.266, 'pos': 0.734, 'compound': 0.8516}
Score for Review #2: {'neg': 0.63, 'neu': 0.37, 'pos': 0.0, 'compound': -0.7783}Based on the compound scores you can see that review1 is a positive review and review2 is a negative review.
Based on the score the classifier confirms that the first review has a more positive sentiment than the second review.
The review that has a more positive sentiment is Review #1: "I love this product! It's amazing."You can play with the code and pass different sentences to see different results.
How Do You Identify Sentences in Text Using Python NLTK?
In the first example of this tutorial, we used a word tokenizer when analyzing the tokens in a sentence.
The NLTK library also provides a sentence tokenizer that allows identifying sentences within a text string instead of simple words.
Let’s see how the same text can be split based on words or sentences.
from nltk.tokenize import word_tokenize
from nltk.tokenize import sent_tokenize
text = "NLTK stands for Natural Language Toolkit. Today we will learn about Python Sentiment Analysis with NLTK."
words = word_tokenize(text)
sentences = sent_tokenize(text)
print("Words: ", words)
print("Sentences: ", sentences)Here is the output:
Words: ['NLTK', 'stands', 'for', 'Natural', 'Language', 'Toolkit', '.', 'Today', 'we', 'will', 'learn', 'about', 'Python', 'Sentiment', 'Analysis', 'with', 'NLTK', '.']
Sentences: ['NLTK stands for Natural Language Toolkit.', 'Today we will learn about Python Sentiment Analysis with NLTK.']To get the words for each sentence you can apply word_tokenize to every sentence using a list comprehension.
words_in_sentences = [word_tokenize(sentence) for sentence in sentences]
print("Words in sentences: ", words_in_sentences)The NLTK library provides a list of lists where the words in the first list are the words in the first sentence and the words in the second list belong to the second sentence.
Words in sentences: [['NLTK', 'stands', 'for', 'Natural', 'Language', 'Toolkit', '.'], ['Today', 'we', 'will', 'learn', 'about', 'Python', 'Sentiment', 'Analysis', 'with', 'NLTK', '.']]How Do You Extract the Frequency of Words With NLTK?
What else can we do with text analysis in Python?
Imagine you want to identify the frequency distribution of each word in a document.
To identify the frequency distribution of tokens in a text you can use nltk.probability.FreqDist available in the NLTK library.
Before calling the FreqDist function you have to extract tokens from the text in the way you have learned in this tutorial.
Then you can pass the list of tokens to the FreqDist function (that accepts an iterable of tokens).
from nltk.tokenize import word_tokenize
from nltk.probability import FreqDist
text = "NLTK stands for Natural Language Toolkit. Today we will learn about Python Sentiment Analysis with NLTK."
words = word_tokenize(text)
frequency_distribution = FreqDist(words)
print(frequency_distribution)If you execute this program you get the following:
<FreqDist with 16 samples and 18 outcomes>What can we do with the data returned by FreqDist?
One useful thing we can do is to plot the frequency distribution of each token in the text using FreqDist.plot().
frequency_distribution.plot()You will see the following graph.
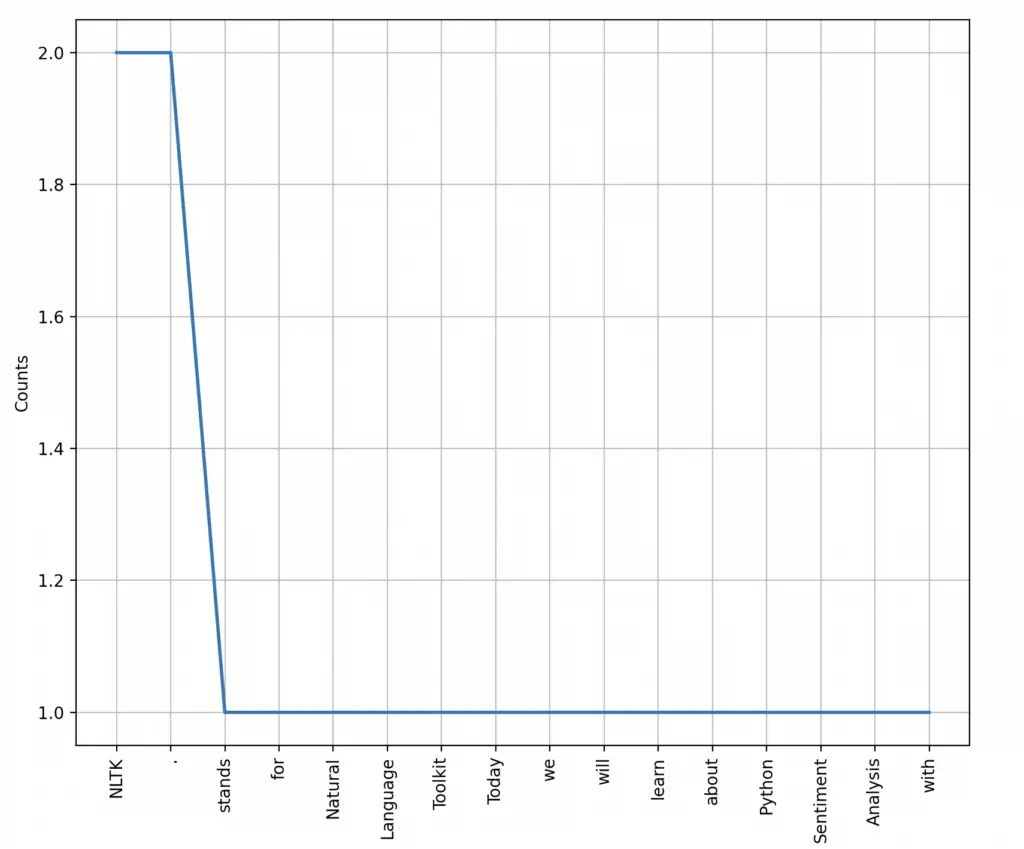
Conclusion:
In this post, we covered the fundamentals of sentiment analysis using Python with NLTK.
We learned how to install and import Python’s Natural Language Toolkit (NLTK), as well as how to analyze text and preprocess text with NLTK capabilities like word tokenization, stopwords, stemming, and lemmatization.
In addition, we classified the sentiment of our text data using NLTK’s pre-trained sentiment analysis classifier.
Businesses may use sentiment analysis to learn what their customers think and feel about the goods and services they provide.

Claudio Sabato is an IT expert with over 15 years of professional experience in Python programming, Linux Systems Administration, Bash programming, and IT Systems Design. He is a professional certified by the Linux Professional Institute.
With a Master’s degree in Computer Science, he has a strong foundation in Software Engineering and a passion for helping others become Software Engineers.